An introduction to byzantine fault tolerance and alternative consensus
What can we expect from distributed systems?
In the blockchain space, you may have heard of a genre of consensus mechanisms known as “BFT-based proof-of-stake,” used by algorithms like Tendermint and Casper. To build up an understanding of what that entails, we must start by analyzing the theoretical foundation of consensus algorithms in blockchain systems, which is traditional Byzantine fault tolerance research.

Byzantine fault tolerance
A blockchain requires a mechanism to reach distributed consensus, or validate and agree on a single chain. Byzantine fault tolerance (BFT) refers to the characteristic of distributed systems that allows them to reach consensus in the face of Byzantine faults, i.e. in situations where components of the system may fail, and not just fail-stop — Byzantine-faulty nodes act arbitrarily and often present conflicting information to different nodes in the system.
BFT gets its name from the Byzantine Generals Problem, the hypothetical scenario in which the army of the Byzantine empire has multiple separate divisions surrounding an enemy city, and they have to all agree on a common plan to attack or retreat. All, or at least nearly all, must perform the same action or they will risk complete failure. The catch is the generals of each division can only communicate with each other individually via messenger, and there may be traitorous generals who send different information to different generals.

The original Byzantine Generals Problem paper by Lamport, Shostak, and Pease proves that no solution with fewer than 3m + 1 generals can cope with m traitors; i.e., consensus is impossible to achieve if ⅓ or more of the generals are traitors.
There is a 1:1 mapping between a typical blockchain network and the Byzantine generals scenario:
objective(generals) = agree on a strategy
objective(blockchain) = agree on valid transactionsspatiality(generals) = distributed camps
spatiality(blockchain) = distributed nodes in the networkloyalists(generals) = honest generals
loyalists(blockchain) = honest nodestraitors(generals) = traitorous generals
traitors(blockchain) = malicious nodesattack(generals) = corrupting a message
attack(blockchain) = adding an invalid transaction to the blockchainproblem(generals) = what message is true?
problem(blockchain) = what transaction is valid?
A solution to the problem Bitcoin and Ethereum currently implement is proof-of-work (PoW), which requires consumption of a resource external to the system, hashing power, to solve “difficulty” problems in order to win the ability to create (transaction-filled) blocks. This allows the respective system to reach consensus on the chain (of blocks) with the largest combined difficulty, i.e. the longest chain.
Correctness of distributed systems
Let’s step back and look at “correctness” properties of distributed systems, like the Byzantine army or the Bitcoin network. As shown in “Proving the Correctness of Multiprocess Programs” by Leslie Lamport (1977), the correctness of distributed (i.e. concurrent, multiprocess) systems can be described in terms of liveness and safety. Both properties must be satisfied for the system to achieve a strict and ideal sense of correctness.
A liveness property is a guarantee that something good will eventually happen. Examples include: a guarantee that a computation will eventually terminate; that the customer will eventually be served; that some candidate will eventually be elected to a political office. In a system where the goal is consensus, a liveness property would be a guarantee that each component will eventually decide on a value (this can be referred to as “termination”).
A safety property is a guarantee that something bad will never happen. Examples include: a guarantee that a system will never deadlock; that an innocent person will never be convicted of a crime. In consensus, a safety property would be a guarantee that different components will never decide on different values (this can be referred to as “agreement”).
FLP impossibility
The next development in distributed system correctness is the FLP impossibility, named after Fischer, Lynch, and Paterson, who described this result in their 1985 paper “Impossibility of Distributed Consensus with One Faulty Process.”
The FLP impossibility states that both termination and agreement (liveness and safety) cannot be satisfied in a time-bound manner in an asynchronous distributed system, if it is to be resilient to at least one fault (they prove their result for general fault tolerance, which is weaker than BFT, since it only requires one fail-stop node — so BFT is included inside FLP impossibility claims).
In asynchronous systems, there is no upper bound on the amount of time components (nodes, generals) may take to receive, process, and respond to messages. Note that synchronous systems can be made fault tolerant, and they can be made Byzantine fault tolerant with the usual <⅓ faulty nodes. Assuming synchronicity of a network is a very strong, unrealistic assumption for, say, Bitcoin, which is designed to work on a network with message delays.
CAP theorem
Another related development is the CAP theorem by Eric Brewer (2000). It states something similar to the FLP impossibility — that you cannot have the correctness properties of consistency, availability, and partition tolerance all at once in an asynchronous distributed database. At most, two of the three properties can be satisfied.
Consistency is a guarantee that reading from each node will return the correct (most recent) write (a guarantee that nothing bad will ever happen).
Availability is a guarantee that reading from any node will return some response (a guarantee that something good will eventually happen).
Partition tolerance is a guarantee that the system will still operate in the face of a network partition, across which some messages between nodes cannot be delivered (fault tolerance).
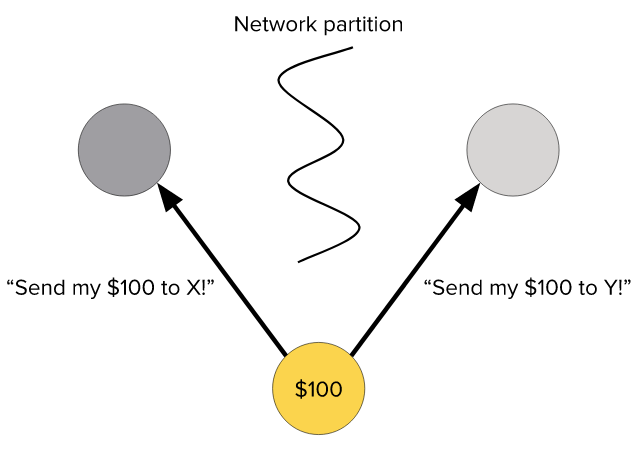
Here’s a simple example of CAP theorem in action. Given a partitioned network, there’s a tradeoff between consistency and availability. If I’m the yellow node, and I have $100, I tell each of the gray nodes to send the same $100 to different addresses. The system either won’t be consistent, because each half sees a different transaction, or it won’t be available, because only one or neither transaction will be agreed upon. (This is looking like the Byzantine generals problem. Note that partition tolerance doesn’t entail the existence of Byzantine faults.)
Overview
By CAP theorem, fault tolerant (partitioned network) consensus (availability and consistency) is unachievable in asynchronous systems. By FLP impossibility, fault tolerant (single fault) consensus (termination and agreement) is unachievable in asynchronous systems.
FLP impossibility seems to be the superset of CAP theorem, since it makes impossibility claims about weaker systems — FLP-admissible systems need only one faulty node, and messages can be delayed but not dropped (there is no network partition). CAP theorem, thus, appears to be a particular instance of FLP impossibility, and both are examples of the fundamental fact that you cannot achieve both liveness and safety in an unreliable distributed system.
Early BFT solutions
Some early solutions to Byzantine faults include the family of consensus protocols known as Paxos (1989)— it uses the common fault tolerant method of state machine replication involving several roles, a quorum rule, and two “promise” and “accept” phases in which nodes communicate to learn an agreed value. Byzantine Paxos is an extension of Paxos that accounts for Byzantine faults. Safety (consistency) is guaranteed — as is the case with any state machine replication, where the nodes must reach agreement to come to consensus. By FLP impossibility, liveness is not guaranteed. Raft (2013) is meant to be a simplified, easy-to-understand version of Paxos.
Practical Byzantine Fault Tolerance (1999) is another state machine replication approach to fault tolerance, also containing a quorum rule and a multi-phase learning process. It guarantees both liveness and safety, but it relies on a weak form of synchrony.
Nakamoto consensus
To further apply what we know about safety and liveness, let’s look at some existing consensus mechanisms that blockchains use. “Nakamoto consensus,” as it is colloquially called, refers to Satoshi Nakamoto’s original PoW consensus, in which the first announced valid block containing a solution to a predetermined computational puzzle is considered correct, and the longest chain is considered the canonical chain. In PoW, simultaneously found solutions and malicious mining lead to forks. Thus, it favors liveness (availability) over safety (consistency).
Nakamoto consensus can be generalized to refer to “chain-based” consensus, in which the protocol states that you must choose among several possible chains. Thus, when proof-of-stake (PoS) initially became a popular alternative to PoW, because it doesn’t require waste of the vast computing power that PoW requires, the first PoS consensus algorithms were chain-based. In Nakamoto-based PoS, the consensus algorithm pseudo-randomly selects a stakeholder (in proportion to their stake) and assigns them the right to create a single block. It is, in a sense, “simulated PoW.” Again, network delays and deviant actors will lead to inevitable forks. Thus, Nakamoto-based PoS favors liveness (availability) over safety (consistency).
What many people began to realize was that Nakamoto consensus was necessary for PoW, but not PoS. Since Nakamoto PoS, in its naive form, suffers from the “nothing at stake” problem and long-range attacks, people sought a new way to achieve PoS without relying on chain selection. In comes BFT-based PoS, or, technically, state-machine-replication-based PoS— which was an old innovation!
“In BFT-style proof of stake, validators are randomly assigned the right to propose blocks, but agreeing on which block is canonical is done through a multi-round process where every validator sends a “vote” for some specific block during each round, and at the end of the process all (honest and online) validators permanently agree on whether or not any given block is part of the chain. Note that blocks may still be chained together; the key difference is that consensus on a block can come within one block, and does not depend on the length or size of the chain after it.” — PoS FAQ
BFT-based PoS favors safety (consistency) over liveness (availability). Can you deduce why?
Nakamoto-based proof-of-stake examples
- Peercoin (2012): Peercoin is the first known implementation of a hybrid PoS/PoW cryptocurrency. It uses coin age consumed by a transaction as proof of stake as well as centrally broadcasted “checkpoints.”
- NXT (2014): NXT uses an account’s effective balance, not coin age, as part of its block creation algorithm.
- Slasher (2014): Slasher is Vitalik Buterin’s punitive PoS algorithm which uses security deposits and “weak subjectivity” to combat the nothing at stake problem and long-range attacks.
- Bitshares (circa 2015): Bitshares uses “delegated-proof-of-stake.” It’s a “technological democracy,” in which stakeholders vote (via transactions) on trusted delegates to sign blocks.
- Tezos (2014): Tezos uses a mix of Slasher, “chain-of-activity,” and “proof-of-burn.”
- Ouroboros (2017): Ouroboros is “a provably secure proof-of-stake blockchain protocol”; it’s chain-based and uses synchronous settings.

BFT-based and “other” proof-of-stake examples
- Tendermint (2014): Tendermint is a mostly asynchronous, BFT consensus protocol with voting power denominated in validator stake; it has a two-stage voting process; it favors safety (consistency). Tendermint is used in the blockchain network Cosmos.
- Casper (2015): Casper is Ethereum’s to-be-released Nakamoto/BFT hybrid PoS algorithm; it favors liveness (availability); it is named after the friendly “GHOST,” as it incorporates properties of the GHOST (Greedy Heaviest Observed Sub-Tree) protocol.
- Algorand (2017): Algorand’s PoS is based on (a novel and fast) message-passing Byzantine agreement. It’s neither hybrid nor fully Nakamoto/state machine replication. Feel free to tackle the whitepaper and explain it to me (I can also refer those interested to study groups reading this whitepaper).

Update: an alternative approach of mine to presenting the information in blog post can be found here.
